팔란티어 파운드리로 공공입찰 데이터 온톨로지 구축하기
나라장터 공공입찰 데이터를 팔란티어 파운드리에 올려 온톨로지를 구축했다. 데이터 정제부터 Pipeline Builder, Object/Link 생성, AIP Logic과 Agent 분석, Workshop 대시보드까지 실제 작업 과정을 순서대로 정리한다.


나라장터에서 데이터를 내려받는 건 누구나 할 수 있다. 그걸 팔란티어 파운드리(Palantir Foundry)에 올려서 온톨로지로 만드는 건 다른 이야기다.
2025년 3월 1일부터 15일까지 반보름치 공공입찰 데이터를 Foundry에 넣고, AIP로 분석하고, Workshop에서 대시보드까지 뽑아봤다.
시리즈 1편에서 다룬 Object, Link, Action의 개념이 실제 데이터에서 어떻게 작동하는지, 작업 순서대로 기록한다. (모든 내용은 우리팀 Angela님이 정리해 주신 내용)
원시 데이터 올리기와 정제
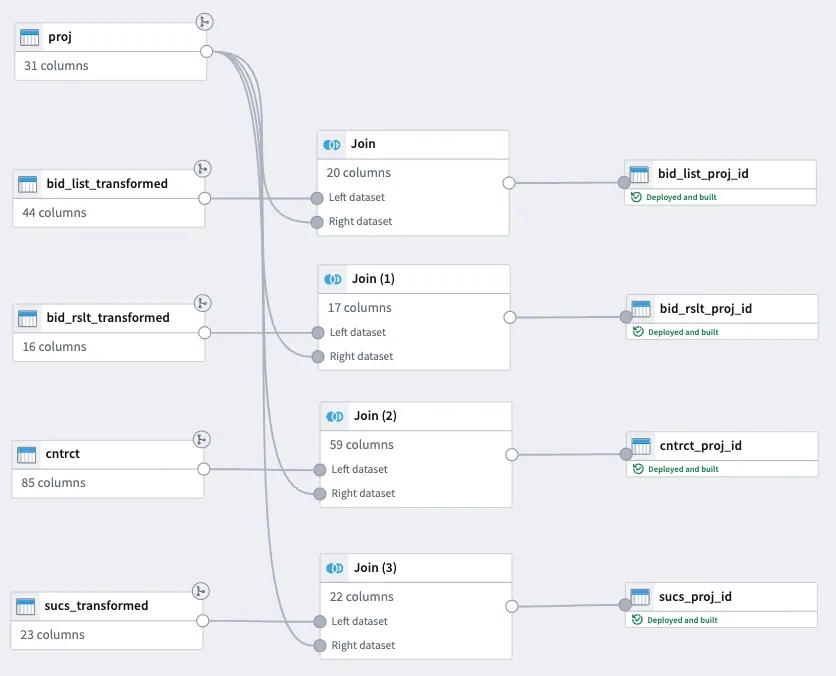
Foundry에 데이터를 올리는 건 간단하다. CSV, JSON, 데이터베이스 커넥터 등 다양한 포맷을 지원한다. 나라장터 데이터는 CSV로 내보내서 Foundry의 Dataset으로 업로드했다. 사전규격, 입찰공고, 개찰결과, 계약 데이터를 각각 별도 Dataset으로 올렸다.
문제는 정제였다.
나라장터 원시 데이터는 칼럼명이 한글이고, 날짜 포맷이 들쭉날쭉하고, 같은 기관이 약간씩 다른 이름으로 들어가 있었다. "서울특별시교육청"과 "서울시교육청"이 따로 노는 식이다. 이 정제 작업이 전체 프로젝트에서 가장 오래 걸렸다. 체감상 전체 시간의 절반 넘게 여기에 들어갔다.
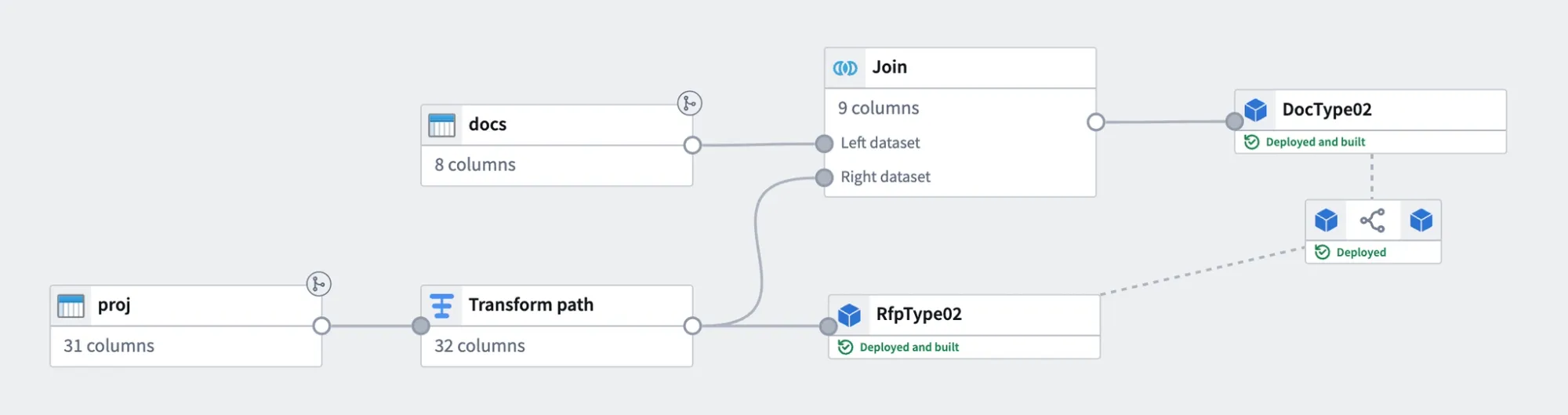
Foundry에서 데이터 정제는 두 가지 방법으로 할 수 있다. Pipeline Builder(노코드)와 Code Repository(Python/SQL)다. 복잡한 정제 로직은 Code Repository에서 PySpark로 처리하고, 단순 변환은 Pipeline Builder에서 끝냈다.
Pipeline Builder로 데이터 변환하기
Pipeline Builder는 Foundry의 노코드 데이터 변환 도구다. 드래그앤드롭으로 노드를 연결해서 데이터를 필터링하고, 조인하고, 칼럼을 추가하거나 변환한다. SQL을 모르는 사람도 데이터 가공이 가능하다는 게 팔란티어가 강조하는 포인트다.
실제로 써보니 단순 변환에는 꽤 편했다. 날짜 포맷 통일, 불필요한 칼럼 제거, 기관명 정규화 같은 작업을 시각적으로 처리했다. 입력 Dataset과 출력 Dataset 사이에 변환 노드를 연결하면, 파이프라인이 실행될 때마다 최신 데이터에 같은 로직이 자동 적용된다.
다만 한계도 있었다. 기관명처럼 유사한 문자열을 하나로 합치는 fuzzy matching 같은 로직은 Pipeline Builder만으로 처리하기 어렵다. 이 부분은 Python 함수를 짜서 Code Repository에서 처리한 뒤, 그 결과를 Pipeline Builder에 연결하는 방식으로 해결했다.
Object와 Link 생성
정제된 데이터셋이 준비되면 온톨로지를 만든다. Foundry의 Ontology Manager에서 Object Type을 정의하고, 해당 Object에 매핑될 Dataset과 Property를 지정한다.
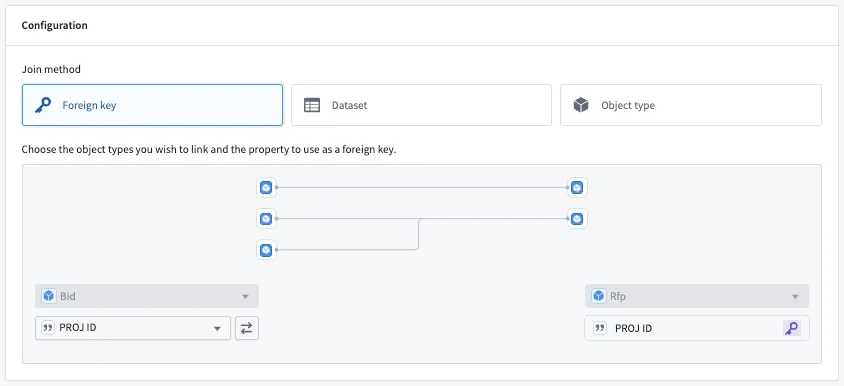
공공입찰 온톨로지에서 잡은 Object Type은 다섯 가지다. 발주기관(Organization), 사전규격(Pre-specification), 입찰공고(Bid Announcement), 투찰(Bid Submission), 낙찰/계약(Award). 각 Object Type에 Primary Key를 걸고 속성을 하나씩 매핑하는 과정이 이어진다. 입찰공고의 경우 공고번호를 Primary Key로 잡았고, 공고명이나 마감일, 추정가격 같은 항목이 속성으로 들어간다.
Link Type 설정은 Object끼리 어떤 관계인지를 정의하는 작업이다. 발주기관과 입찰공고는 1:N, 입찰공고와 투찰도 1:N, 사전규격과 입찰공고는 1:1로 연결했다. Link를 걸 때는 양쪽 Object의 Foreign Key 칼럼을 지정해줘야 한다. 정제 단계에서 키 값을 제대로 통일해두지 않았더니 연결이 누락되는 Object가 꽤 나왔다.
온톨로지가 완성되면 Foundry 내에서 Object를 클릭했을 때 연결된 다른 Object를 바로 탐색할 수 있다. 특정 입찰공고를 열면 어느 기관이 발주했고, 어떤 업체가 투찰했고, 누가 낙찰받았는지 한 화면에서 확인된다.
AIP Logic과 AIP Agent 활용
온톨로지가 잡히면 AIP를 연결할 수 있다. AIP에는 두 가지 모드가 있다. Logic과 Agent.
AIP Logic은 규칙 기반 자동화다. "입찰공고의 RFP에서 구매 물품명을 추출해서 별도 속성으로 저장해"라는 식의 명확한 입력-출력 구조를 정의해두면 LLM이 그 규칙에 따라 실행한다. 반복 업무에 적합하다. 공공입찰 데이터에서는 RFP 원문에서 핵심 요구사항을 뽑아내는 작업에 Logic을 적용했다.
AIP Agent는 자연어 대화형이다. "3월 첫째 주 마감 공고 중 낙찰률이 가장 높았던 업종은?"이라고 물으면, Agent가 온톨로지를 탐색해서 답을 만들어준다. 미리 정의된 규칙 없이, 질문에 맞는 실행 계획을 스스로 세운다. 탐색적 분석에 쓰기 좋다.
둘의 차이를 실무적으로 정리하면 이렇다. Logic은 매일 돌려야 하는 정형화된 업무, Agent는 일회성 질문이나 새로운 각도의 분석에 맞다. 온톨로지가 잘 잡혀 있을수록 Agent의 답변 정확도가 올라간다. 관계(Link)와 이벤트(Action)가 빠져 있으면 Agent는 단편적인 답만 내놓는다.
Workshop 대시보드
분석 결과를 팀과 공유하려면 Workshop을 쓴다. Workshop은 Foundry의 대시보드 빌더로, 온톨로지 데이터를 시각화한다. 테이블, 차트, 지도, 타임라인 같은 위젯을 조합해서 코드 없이 화면을 구성한다.
공공입찰 온톨로지에서 Workshop으로 만든 대시보드 중 하나는 기관별 발주 분석 화면이었다. 특정 기관을 선택하면 그 기관이 낸 입찰공고 목록, 품목별 빈도, 월별 추이가 한 화면에 표시된다. 이 화면을 만드는 데 걸린 시간은 1시간이 안 됐다. 온톨로지가 이미 관계 구조를 갖고 있으니, 위젯에 Object를 연결하고 필터를 거는 것만으로 충분했다.
Workshop의 강점은 온톨로지 기반이라는 점이다. 새로운 데이터가 파이프라인을 통해 들어오면 대시보드가 자동으로 갱신된다. BI 도구에서 데이터 소스를 매번 다시 연결하는 수고가 없다.
시간 배분이 모든 걸 결정했다
15일치 데이터인데도 정제와 온톨로지 설계에 전체 작업 시간의 60% 넘게 들어갔다. 수년치 사내 데이터를 다루는 기업이라면 이 비중이 더 커질 수밖에 없다. 데이터 엔지니어 없이 시작하면 이 단계에서 멈춘다.
반대로, 온톨로지가 잡힌 뒤의 속도는 놀랍다. 기관별 분석 대시보드를 Workshop에서 만드는 데 1시간이 안 걸렸다. AIP에 새로운 질문을 던지면 몇 분 안에 답이 나왔다. 이 비대칭이 Foundry를 쓰는 이유다. 다음 편에서는 이걸 실제로 도입할 때 부딪히는 비용, 파트너십, 온프레미스 운영 문제를 다룬다.
자주 묻는 질문
팔란티어 파운드리 Pipeline Builder란?
- Pipeline Builder는 Foundry 내 노코드 데이터 변환 도구다. 드래그앤드롭으로 데이터를 정제하고, 조인하고, 필터링할 수 있다. 정제된 데이터를 온톨로지의 Object로 변환하는 중간 단계 역할을 한다.
AIP Logic과 AIP Agent의 차이는?
- AIP Logic은 사전 정의된 규칙 기반으로 자동화를 실행한다. 입력과 출력이 명확한 반복 업무에 적합하다. AIP Agent는 자연어 지시를 받아 스스로 실행 계획을 세우고 처리한다. 탐색적 분석이나 복합적 의사결정에 활용된다.
팔란티어 Workshop은 어떤 도구인가?
- Workshop은 온톨로지 데이터를 시각화하고 운영 대시보드를 만드는 도구다. 테이블, 차트, 지도, 타임라인 같은 위젯을 조합해서 코드 없이 대시보드를 구성한다. 온톨로지 기반이라 데이터가 바뀌면 대시보드도 자동 갱신된다.