MySQL에서 BigQuery로 옮겨 50배 빠른 서비스를 구축한 방법


클라이원트에서 성능이 느려 고객 불만이 많았던 빅데이터 기반 통계 기능의 속도를 최근 BigQuery를 활용하여 크게 개선했습니다.
BigQuery는 처음 접하기에 복잡해 보일 수 있지만, 실제로는 진입 장벽이 낮고 사용하기 편리한데요. 물론 비용이 비싸지만 그만큼 장점이 많습니다. 특히 빅데이터 기반 시스템에서 가장 효과적으로 사용할 수 있으며, 일반 DB의 완전한 대체재로 사용하기는 어렵지만 백엔드를 보완할 수 있는 좋은 해결책이 될 수 있습니다.
얼마나 간단한지, 그리고 비용을 어떻게 최적화할 수 있는지 하나씩 알아볼까요?
아울러, 클라이원트는 성장에 목마른 AI Engineer와Backend Engineer를 모시고 있습니다. 관심 있으신 분들은 아래 링크를 확인해 주시거나, 이메일을 보내주세요! 👉 kyle@cliwant.com
직무 개요:
RAG 시스템을 전문으로 하는 엔지니어로서, 수많은 RFP를 청킹(Chunking)하여 벡터 데이터베이스(Vector DB)를 구축합니다. 그리고 GPT, Gemini, Llama 등의 대규모 언어 모델(LLM)을 활용해 자동으로 생성된 답변을 제시하는 솔루션을 함께 개발할 것입니다. RFP와 제안서 생성은 시간이 오래 걸리고 작성할 내용이 많아 클라이원트의 고객들이 가장 큰 어려움을 겪는 분야입니다. 전반적인 시스템 개선을 위해 지속적으로 연구하면서 고객들의 어려움을 해결하는 데 열정이 있는 AI 엔지니어분과 함께하고자 합니다.
역할 및 책임:
- RAG 시스템 설계: 클라이원트의 제품 성능과 확장성을 개선하기 위한 RAG 시스템 설계, 구현 및 최적화.
- 프롬프트 엔지니어링: 다양한 프롬프트를 시도하고 연구해보며 RFP와 제안서에 들어갈 내용에 대한 자동생성을 지속적으로 개선.
- Vector Database 구축: 비정형화되어있는 문서를 RAG에 사용하기 위해 효과적인 Chunking 방식을 연구하고, 자동으로 섹션을 구분하는 로직 구현.
- LLM모델 벤치마킹: LLM 모델들을 (GPT, Gemini, Claude, Llama 등) 벤치마킹하고 비교하며 효과적이면서도 비용 효율적인 솔루션 구축.
- 최신 트렌드 파악 및 적용: 자연어, LLMs 및 RAG 분야에서 최신 기술 동향을 연구하고 업데이트.
지원 자격:
- 학력: 컴퓨터 과학, 인공지능, 머신 러닝 또는 관련 분야의 학사 또는 석사 학위.
- 경험: NLP, 특히 대규모 언어 모델(LLMs)과 RAG에 대한 경험을 보유.
- 기술 역량: Python과 같은 프로그래밍 언어에 대한 숙련도.
- 데이터 기술: 데이터 전처리, 특징 엔지니어링 및 대규모 데이터셋 작업 경험.
- 문제 해결: 뛰어난 분석 및 문제 해결 능력, 비판적이고 창의적으로 생각할 수 있는 능력.
- 팀 플레이어: 팀 지향 환경에서 효과적으로 일할 수 있는 강력한 협업 및 의사 소통 능력.
우대 사항:
- 자연어 처리(NLP) 분야의 전문성을 갖추고 있으며, 언어적 뉘앙스와 기법을 깊이 이해하여 언어 기반 기술을 발전시키는 데 필수적인 능력을 보유한 분.
- 머신러닝 분야에서 MS 또는 PhD 소지, 머신러닝의 원리 및 응용에 대한 깊은 학문적 기초.
- AWS Sagemaker, Bedrock 등 최신 AI 관련 클라우드 서비스 활용 경험.
직무 개요:
클라이원트는 혁신적인 입찰 분석 솔루션을 개발하고 지속적으로 개선하기 위해 경험 많은 개발 팀장을 찾고 있습니다. 이 역할은 AWS를 기반으로 한 백엔드 서버 구축, 빅데이터 DB 설계 및 구축, OpenAI API의 활용, RAG, Regex, Vector DB 등 최신 기술을 활용하여 제품 개발 및 최적화를 주도합니다.
역할 및 책임:
- 다양한 클라우드 인프라 환경(AWS, Azure, GCP)에서의 서비스 설계 및 구축.
- Kubernetes를 통한 효율적인 Microservice 관리 및 배포환경 구축.
- CI/CD 파이프라인을 통한 효율적인 개발 및 배포 프로세스 구현.
- 빅데이터 기반 DB 설계 및 유지 보수.
- RESTful API 개발 및 유지 보수.
- 웹 크롤러 개발 및 관리.
지원 자격:
- 컴퓨터공학 전공 혹은 그에 준하는 전공 및 지식을 보유하신 분.
- 만 5년 이상의 백엔드 개발 경험을 보유하신 분.
- 빅 데이터 기술을 활용한 프로젝트 경험.
- Java/Kotlin/Python 등 하나 이상의 프로그래밍 언어 전문성을 보유하신 분.
- Kubernetes와 같은 컨테이너 오케스트레이션 도구를 사용한 배포 시스템 구축 경험.
- 탁월한 문제 해결 능력, 강력한 팀워크 및 커뮤니케이션 스킬.
우대 사항:
- GCP Big Query를 이용한 빅데이터 분석 및 BI 툴 개발 경험.
- OpenAI 활용 프롬프트 엔지니어링을 통해 문서 내 주요 정보 추출 경험.
- RAG, Regex, Vector Database 등을 활용한 복잡한 데이터 처리 및 검색 엔진 구축 경험.

Introduction
BigQuery는 MySQL보다 몇백 배나 빠른 성능을 제공하지만, 쿼리당 비용이 발생합니다. 따라서 빅데이터 셋에 적합하며, BI 성의 통계 기능을 제공할 때 가장 큰 효과를 볼 수 있습니다. 하지만 쿼리 최적화를 하지 않으면 비용이 기하급수적으로 증가할 수 있어 최적화는 필수입니다. 이번 글에서는 클라이원트가 BigQuery로 어떤 문제를 어떻게 해결했는지, 그리고 어떻게 최적화했는지를 상세히 설명합니다.
Problem
일반 SQL DB로 빅데이터를 다룰 때 항상 가장 어려운 부분은 빠른 조회 속도인데요.
특히 대량의 데이터가 담긴 테이블 전체를 특정 조건에 따라 어그리게이션(Aggregation) 하거나 정렬(Ordering)해야하는 니즈가 있다면 인덱스를 전략적으로 잘 설정해야하고, 쿼리 또한 효율적으로 짜야 퍼포먼스가 잘 나옵니다.
하지만 위 방법도 결국 한계가 오는 때가 옵니다. 아무리 최적화를 해도 더 이상 개선할 여지가 없을 때를 맞이하기 마련인데요. 저희도 이 문제를 피해갈 수 없었습니다. 클라이원트의 BI 서비스 중 2020년부터 수집한 최대 750만개의 과거 사업 내용을 실시간으로 검색하고 수요처, 발주 기관 등으로 총 공고 수 및 사업금액 등의 어그리게이션 하여 통계를 매겨야하는 니즈가 있었습니다.
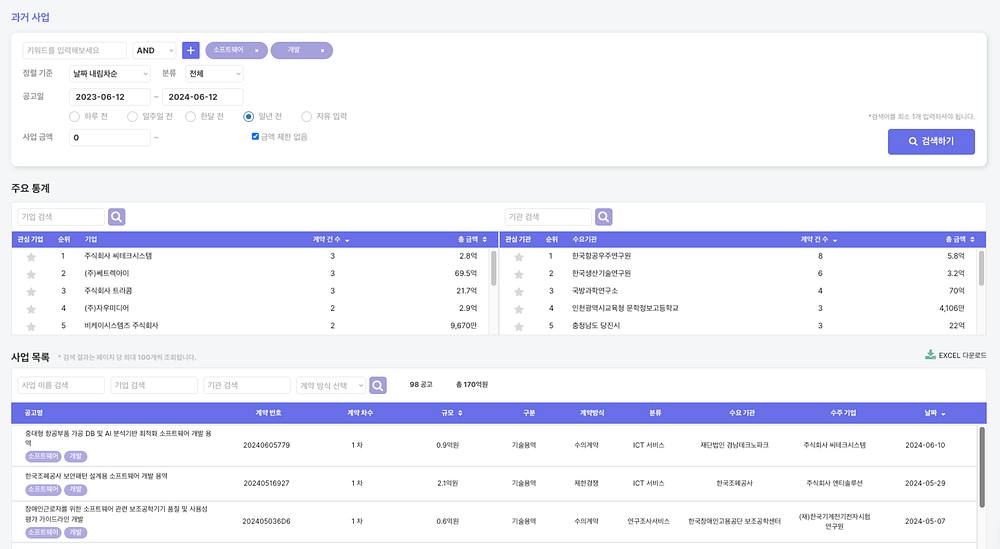
문제는 특정 키워드와 공고일 범위로 검색할 경우 결과가 나오기까지 60초가 넘어가 Timeout 에러까지 발생하는 현상이 있었습니다. API로 데이터를 반환해야하는 상황에서 10초가 넘어가는 것도 서비스에 크리티컬한데 이런 상황은 거의 서비스가 불가능할정도였죠.
아래는 MySQL 기준으로 검색했을 때 Cache Limit 문제로 키워드 검색이 안된 예시입니다.
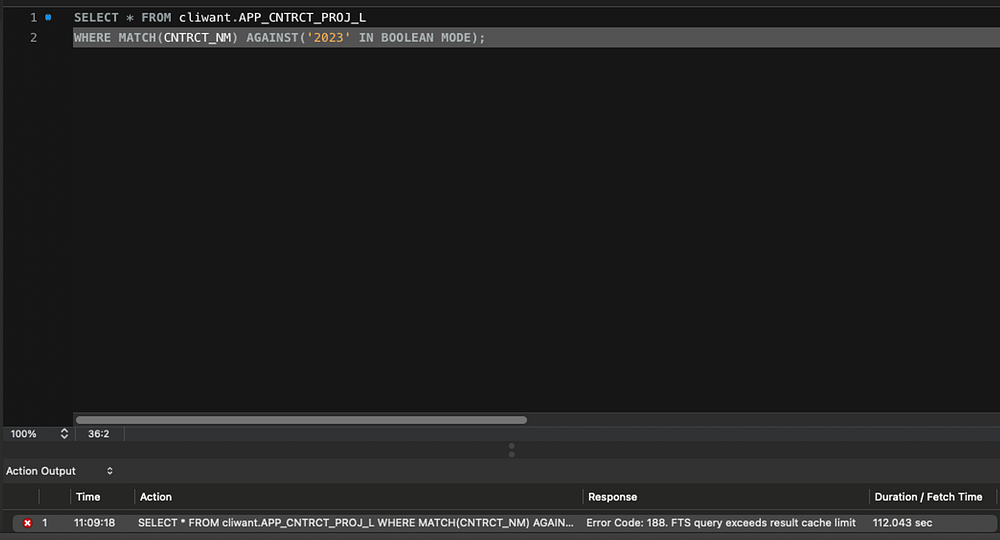
따라서 검색 쿼리를 뜯어보니 아래와 같은 단계가 있었고, 각 단계별로 최적화가 필요한 것을 발견했습니다.
- 입력된 키워드 기준으로 공고명과 다양한 필터로 공고 검색
- 기업별, 수요기관별 총 공고 개수 및 금액 어그리게이션
- 업로드 날짜, 금액 기준으로 정렬
문제는 첫번째 단계를 해결 하는데서부터 막혔다는 것입니다. 750만개 문서 중 자주 발생하는 키워드를 입력했을 경우 탐색하는 데이터량 자체가 너무 많아서 조회 자체가 오래걸렸습니다.
Solution
1. Bigquery 의 효과
다양한 방법을 고민해보았습니다.
- 미리 데이터를 추출해놓는 방법은 없을까? → 유저가 어떤 키워드랑 필터 조건을 걸지 모른다
- ElasticSearch를 활용해볼까? → 처음부터 배우고 PoC진행하기까지 너무 오래걸린다. 샤딩 방법이랑 쿼리 문법 등을 다 처음부터 배워야했다
- 쿼리를 최적화 해볼까? → 빅데이터를 다루다보면 쿼리로 최적화로 개선할 수 있는데 한계가 있더라
고민에 빠져있던 와중에 GCP BigQuery가 빅데이터 기반 쿼리를 작성하는데 빠르다는 이야기를 들었지만, 사실 반신반의했습니다. 같은 SQL 기반인데 얼마나 빠를 수 있을까? 그래도 테이블만 그대로 옮기고 쿼리도 MySQL 기반과 거의 유사해서 주요 테이블 하나만 마이그레이션해서 테스트해보았습니다.
깜짝 놀랐습니다. 아무런 인덱스도 걸지 않았는데 타임아웃이 걸리던 쿼리가 1초 만에 돌아가는 것이었습니다. 심지어 GROUP BY로 통계를 매기는 쿼리도, ORDER BY로 전체 데이터를 정렬하는 쿼리도 똑같이 빠르게 실행되었습니다.
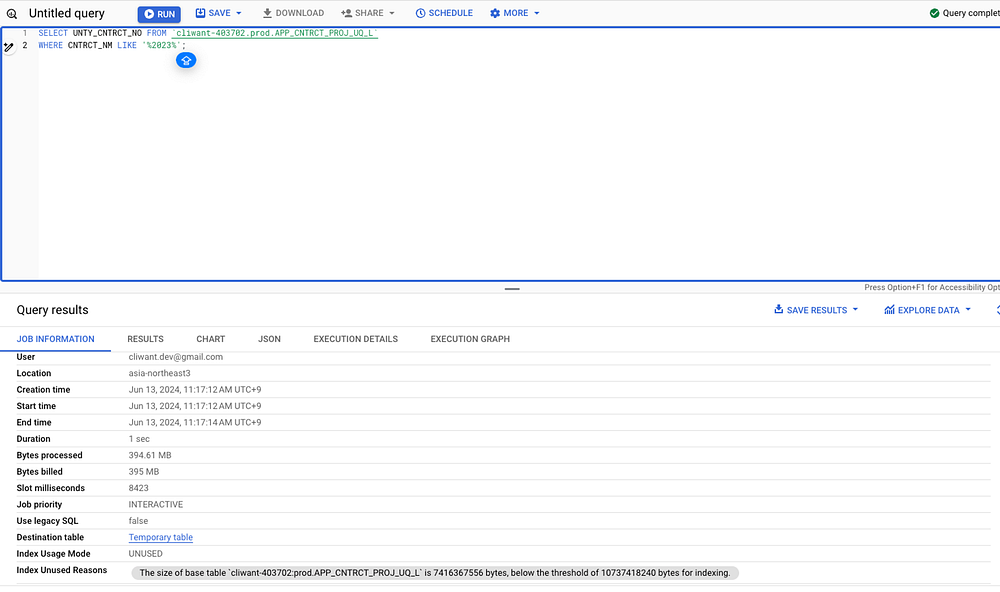
2. 작동 원리
MySQL같은경우 하나의 엔진에서 처리하지만 BigQuery는 여러개의 Compute Engine에서 병렬로 쿼리를 실행시킨 후 결과를 조합해서 보여주는 원리라 가능하다고 합니다.
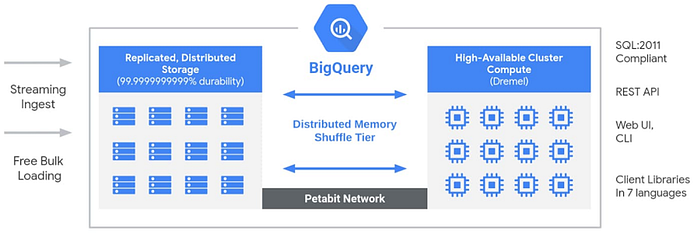
하지만 병렬로 처리하는 만큼 쿼리 하나하나에 컴퓨팅 자원이 많이 소모되기 때문에 BigQuery는 속도가 빠른 대신에 쿼리 한번 날릴때마다 비용이 발생합니다.
비용은 쿼리 실행 시 데이터를 조회한 양에 비례해서 발생하고, 1TB 당 대략 8500원정도의 비용입니다. 따라서 위 쿼리 한번 실행 시 400MB 데이터를 조회하는데 3.4원의 비용이 발생했습니다. 300번의 쿼리를 날리면 1000원정도의 비용이 발생한다고 봤을 때 비용이 비싼편은 맞습니다.
추가로 조회하는 컬럼을 늘리거나 조건을 추가할 경우, 더 많은 데이터를 조회하기 때문에 총 조회하는 데이터량이 늘어나서 쿼리 비용이 더 비싸집니다.
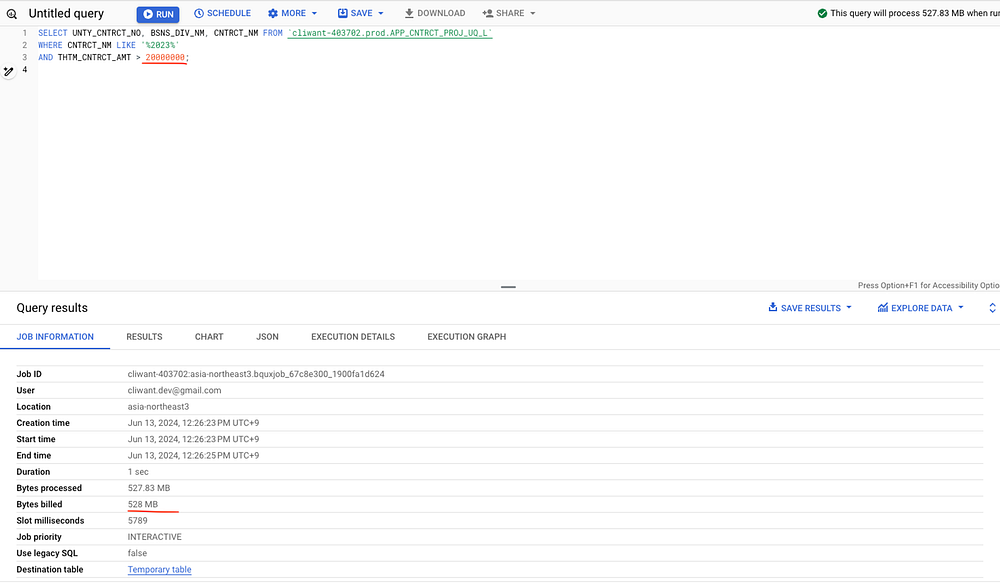
3. 그러면 비용 최적화는 어떤식으로 해야하는가?
BigQuery 테이블 생성 시 파티셔닝 옵션을 날짜 or 숫자 필드에 걸 수 있습니다.
테이블 자체를 해당 필드 기준으로 분해해서, 쿼리 시 해당 필드에 조건을 거는 방법으로 조회되는 데이터 범위를 좁힐 수 있게 됩니다. 예를들어 RGST_DT (업로드 날짜) 기준으로 1달씩 테이블을 파티셔닝 했을 때, 5월치 데이터에 대한 조건을 걸면 5월에 해당하는 데이터에만 비용이 발생하게 됩니다.
아래 스크린샷을 보시면 조회된 데이터가 12MB밖에 되지 않아 33배정도 비용을 절감한 것을 보실 수 있습니다.
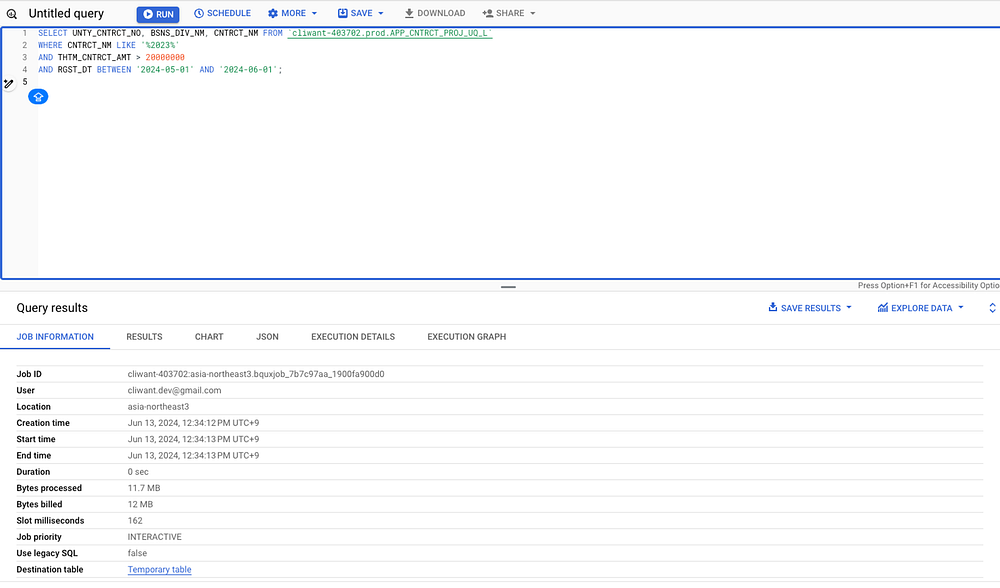
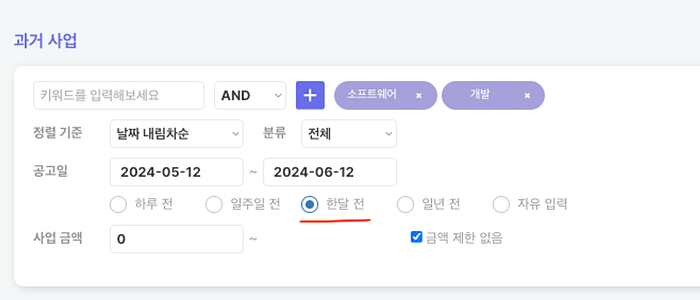
추가로 서비스에서 1달 기준으로 기본 날짜 범위를 설정해두어 전체 조회하는 빈도수를 줄인다면 비용을 더 절감할 수 있겠죠. 🙂
Conclusion
BigQuery는 말그대로 Big 데이터를 조회할 때 가장 효과적입니다. 생각보다 셋업하는것도 쉽고, 쿼리도 SQL 문법 그대로 사용할 수 있기 때문에 진입장벽이 높지도 않습니다. (역시 갓구글 🙏)
다만 성능이 좋은만큼 비용이 많이 발생하는 것도 사실이니 조회하는 데이터를 줄이고, 파티셔닝도 자주 사용되는 필드 기준으로 설정해두어서 서비스에 활용하려면 비용 최적화는 꼭 신경써야 하는 부분입니다.
BigQuery가 MySQL같은 일반 DB를 대체로 사용하기에는 효과적이지 않다고 여겨집니다. 가벼운 쿼리도 실행할 때마다 비용이 발생하고, 가벼울수록 MySQL 이 더 빠르기 때문입니다. 따라서 BigQuery가 꼭 필요한 기능들 위주로 일반 DB와 같이 사용하는게 효과적입니다.
직무 개요:
RAG 시스템을 전문으로 하는 엔지니어로서, 수많은 RFP를 청킹(Chunking)하여 벡터 데이터베이스(Vector DB)를 구축합니다. 그리고 GPT, Gemini, Llama 등의 대규모 언어 모델(LLM)을 활용해 자동으로 생성된 답변을 제시하는 솔루션을 함께 개발할 것입니다. RFP와 제안서 생성은 시간이 오래 걸리고 작성할 내용이 많아 클라이원트의 고객들이 가장 큰 어려움을 겪는 분야입니다. 전반적인 시스템 개선을 위해 지속적으로 연구하면서 고객들의 어려움을 해결하는 데 열정이 있는 AI 엔지니어분과 함께하고자 합니다.
역할 및 책임:
- RAG 시스템 설계: 클라이원트의 제품 성능과 확장성을 개선하기 위한 RAG 시스템 설계, 구현 및 최적화.
- 프롬프트 엔지니어링: 다양한 프롬프트를 시도하고 연구해보며 RFP와 제안서에 들어갈 내용에 대한 자동생성을 지속적으로 개선.
- Vector Database 구축: 비정형화되어있는 문서를 RAG에 사용하기 위해 효과적인 Chunking 방식을 연구하고, 자동으로 섹션을 구분하는 로직 구현.
- LLM모델 벤치마킹: LLM 모델들을 (GPT, Gemini, Claude, Llama 등) 벤치마킹하고 비교하며 효과적이면서도 비용 효율적인 솔루션 구축.
- 최신 트렌드 파악 및 적용: 자연어, LLMs 및 RAG 분야에서 최신 기술 동향을 연구하고 업데이트.
지원 자격:
- 학력: 컴퓨터 과학, 인공지능, 머신 러닝 또는 관련 분야의 학사 또는 석사 학위.
- 경험: NLP, 특히 대규모 언어 모델(LLMs)과 RAG에 대한 경험을 보유.
- 기술 역량: Python과 같은 프로그래밍 언어에 대한 숙련도.
- 데이터 기술: 데이터 전처리, 특징 엔지니어링 및 대규모 데이터셋 작업 경험.
- 문제 해결: 뛰어난 분석 및 문제 해결 능력, 비판적이고 창의적으로 생각할 수 있는 능력.
- 팀 플레이어: 팀 지향 환경에서 효과적으로 일할 수 있는 강력한 협업 및 의사 소통 능력.
우대 사항:
- 자연어 처리(NLP) 분야의 전문성을 갖추고 있으며, 언어적 뉘앙스와 기법을 깊이 이해하여 언어 기반 기술을 발전시키는 데 필수적인 능력을 보유한 분.
- 머신러닝 분야에서 MS 또는 PhD 소지, 머신러닝의 원리 및 응용에 대한 깊은 학문적 기초.
- AWS Sagemaker, Bedrock 등 최신 AI 관련 클라우드 서비스 활용 경험.
직무 개요:
클라이원트는 혁신적인 입찰 분석 솔루션을 개발하고 지속적으로 개선하기 위해 경험 많은 개발 팀장을 찾고 있습니다. 이 역할은 AWS를 기반으로 한 백엔드 서버 구축, 빅데이터 DB 설계 및 구축, OpenAI API의 활용, RAG, Regex, Vector DB 등 최신 기술을 활용하여 제품 개발 및 최적화를 주도합니다.
역할 및 책임:
- 다양한 클라우드 인프라 환경(AWS, Azure, GCP)에서의 서비스 설계 및 구축.
- Kubernetes를 통한 효율적인 Microservice 관리 및 배포환경 구축.
- CI/CD 파이프라인을 통한 효율적인 개발 및 배포 프로세스 구현.
- 빅데이터 기반 DB 설계 및 유지 보수.
- RESTful API 개발 및 유지 보수.
- 웹 크롤러 개발 및 관리.
지원 자격:
- 컴퓨터공학 전공 혹은 그에 준하는 전공 및 지식을 보유하신 분.
- 만 5년 이상의 백엔드 개발 경험을 보유하신 분.
- 빅 데이터 기술을 활용한 프로젝트 경험.
- Java/Kotlin/Python 등 하나 이상의 프로그래밍 언어 전문성을 보유하신 분.
- Kubernetes와 같은 컨테이너 오케스트레이션 도구를 사용한 배포 시스템 구축 경험.
- 탁월한 문제 해결 능력, 강력한 팀워크 및 커뮤니케이션 스킬.
우대 사항:
- GCP Big Query를 이용한 빅데이터 분석 및 BI 툴 개발 경험.
- OpenAI 활용 프롬프트 엔지니어링을 통해 문서 내 주요 정보 추출 경험.
- RAG, Regex, Vector Database 등을 활용한 복잡한 데이터 처리 및 검색 엔진 구축 경험.
Written by Kyle, CTO @ Cliwant
클라이원트 소식 더 보기
AI 입찰 자동화 솔루션 Contrl을 만드는 클라이원트의 최신 소식을 확인하세요.
Contrl 알아보기 → 도입 문의하기이메일 문의: sales@cliwant.com