Optimizing Contract Risk Analysis with 90% Accuracy through RAG


Many companies are exploring the use of LLMs to streamline the analysis of large, complex documents. Although the idea might seem simple, it introduces a range of challenges. This complexity raises questions about how accurate these tools can truly be and whether they’re ready for high-stakes business environments.
In the past two months, CLIWANT has successfully developed a system capable of analyzing complex English contracts—exceeding 100 pages—with 90% accuracy in identifying risk clauses for our enterprise clients. This project was particularly challenging as it was conducted in an on-premises environment, meaning we couldn’t leverage the extended context length capabilities of the latest GPT or Gemini models. Instead, we had to work within the constraints of Meta's open-licensed model, Llama 3.1.
This blog post delves into the main challenges enterprises face in contract analysis and explains how CLIWANT leveraged AI technology to tackle these issues in a technically sophisticated way.
Problem Definition and Objectives
While we can’t disclose specific company names due to NDAs, the client is a global manufacturer managing large-scale projects with contract values reaching millions of dollars per agreement.
Given the high financial stakes, the contracts are extensive and detailed. In the past, missing even a minor clause led to substantial compensation payments, prompting the client to establish a rigorous checklist of over 200 review items, refined through decades of experience. Currently, each item is meticulously reviewed manually, with examples including:
- In cases of project suspension due to natural disasters or unforeseen events, who holds the liability?
- If defects emerge post-testing, who bears responsibility?
If a clause shifts all responsibility to the client, they could face astronomical liabilities for issues arising during the project.
The goal of this project is clear: to reduce the time needed for reviewing lengthy contracts from an entire day to just five minutes. Additionally, we aim to enhance the speed and accuracy of contract reviews by minimizing human error through an AI-powered system.
Technical Solution
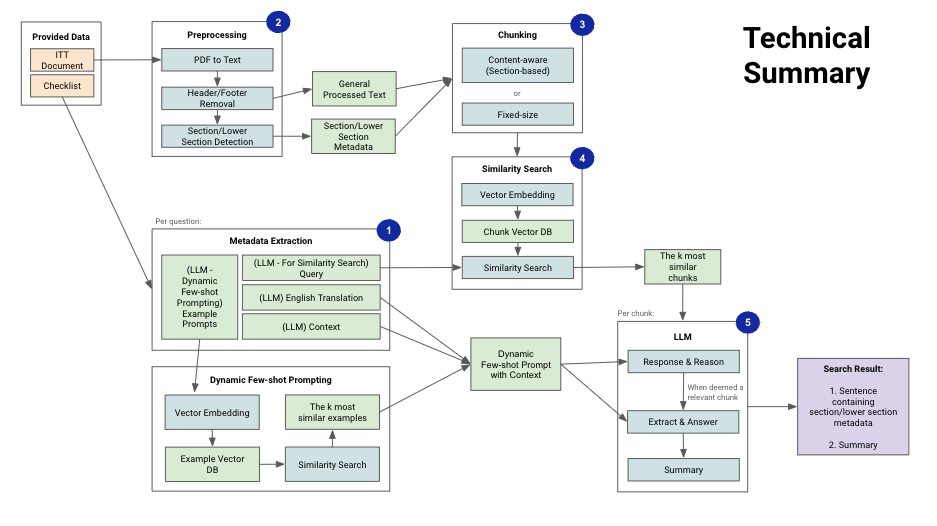
We’ll start with an overview of the architecture and then walk through each component in detail.
This pipeline employs Retrieval-Augmented Generation (RAG), where documents are divided into chunks. Chunks most likely to contain relevant information are retrieved through similarity search and then analyzed by an LLM, which generates the final output.
Architecture Components
- Building metadata for RAG and prompting
- Preprocessing ITT (contract) documents and extracting text
- Text Chunking:
- Context-Aware Chunking: creating chunks while maintaining context
- Fixed-Size Chunking: chunking based on a fixed length (n characters)
- Similarity Search (RAG Search): finding highly relevant portions among extracted chunks
- LLM:
- Chunk Analysis (Llama 70b): conducting in-depth analysis of specific chunks to extract necessary information
- Content Extraction (Llama 70b): precisely selecting relevant information
- Korean Summary (Yanolja): providing a summary in Korean for the final output
1. Building Metadata
Metadata is constructed to align with each review item, with a structure that includes the following elements:
Similarity Search Queries for Chunk Retrieval:
- To create effective similarity search queries, we reference past documents, combining frequently appearing keywords within specific sections or leveraging the full content of relevant sections for search. The most effective query depends on the embedding model used in RAG and the characteristics of the review item.
Question Queries for Relevant Content Extraction:
- These are prompts for the LLM to confirm and summarize information relevant to the review item within each chunk. For instance, a query might ask, "Is there a clause specifying liability in cases of natural disasters (e.g., typhoons, earthquakes)?"
Example Set for Few-Shot Prompting:
- To enhance accuracy, we include related examples extracted from previous contract documents in a few-shot format. This approach has proven effective in helping the LLM grasp context and deliver precise results.
Background Information for Additional Clarity:
- When necessary, we provide additional explanations or contextual details to enhance the LLM's understanding. For example, specifying, "Natural disasters include earthquakes, typhoons, tornadoes, and floods," ensures the LLM interprets the context accurately.
2. Preprocessing and Text Extraction
Contract data may be provided in various formats, such as Word documents and PDFs. To standardize processing, all documents are first converted to PDF format, and raw text is extracted.
During this extraction, elements that could reduce accuracy—such as page numbers and unnecessary annotations—are removed to ensure clean, high-quality data.
Additionally, an algorithm is developed to automatically detect sections within the document, enabling efficient parsing of metadata for each section. This structured approach improves the overall accuracy and reliability of the data processing.

3. Chunking
Chunking is performed based on the automatically detected sections from the preprocessing stage. However, if a section isn’t precisely extracted, we employ an alternative approach: fixed-length chunking based on a set number of characters.
Since target items are typically found within a single section, fixed-length chunking can lead to a loss of context, which may reduce the accuracy of the final output. We apply both chunking methods because, while contract formats are generally consistent, exceptions may arise where documents follow different structures, meaning section detection might not always succeed.
Sections are generally formatted as “#.#,” but to account for cases where alphabetic characters are included, we designed a flexible chunking system to maintain adaptability.

4. Similarity Search
In this step, chunks extracted during the chunking phase are vectorized and compared against the query for the review item, retrieving the top k most similar chunks. For instance, if a 100-page document yields 500 chunks, similarity search identifies chunks containing keywords like "criminal offence" or "legal."
For example, using RAG, we retrieve the top k chunks related to criminal and legal keywords, which are then passed on to the next analysis phase.



5. LLM Review and Summary
In this system, the LLM is employed across three primary stages, with each function designated as an "Agent" in recent terminology.
Stage 1: Validation
- The first validation step is critical for reducing hallucinations and increasing accuracy. The chunks extracted through similarity search in RAG serve as a net to capture relevant information from the entire document. In this step, each chunk’s relevance is thoroughly checked before moving on to the next stage.
- Passing unrelated chunks to Stage 2 increases the risk of summarizing irrelevant content, so we use few-shot prompting with around five examples—showing both relevant and irrelevant cases—to reinforce validation accuracy. Initially, the Llama 3 8b model was used, but due to low validation accuracy, we upgraded to the Llama 70b model, significantly improving precision.
Stage 2: Extraction and Summary of Relevant Information
- From the validated chunks, essential information is precisely extracted and summarized in a user-friendly format. For example, a summary might be as concise as, “Clause 10.3 specifies that neither party is liable in case of a natural disaster.” The summarized content is generated in English, as Llama models currently perform best in this language, particularly in legal contexts.
Stage 3: Korean Translation
- In the final step, the summary from Stage 2 is translated into Korean. Testing showed that LLM models outperform standard translation tools like Papago for this purpose. After experimenting with various models, including KKULM, fine-tuned Llama3, and Solar-based models, we found the Yanolja model to deliver the best results.
- Specifically, the model yanolja/EEVE-Korean-10.8B-v1.0 proved exceptionally suitable for translating legal clauses at a professional level.
Conclusion
Through the methods described above, we successfully built metadata for each item and collaborated with client experts to implement a system capable of identifying risk items with up to 90% accuracy.
While recent solutions like ChatPDF aim to create all-in-one Q&A functionalities for uploaded documents, we believe such approaches may fall short due to their lack of domain-specific nuances and verification for each query. To precisely extract specific information from documents, it is essential to build comprehensive metadata for each item and conduct thorough validation of the source text.
Enterprise clients interested in leveraging LLMs for complex business document analysis on a project basis are welcome to reach out at any time. 😊



![[클라이원트] AI로 1시간 만에 끝내는 입찰 준비 (웨비나 풀버전)](/content/images/size/w600/2024/09/-----------2024-09-26------12.07.42.png)